[Hands-on] 1장. 한 눈에 보는 머신러닝
📌 머신러닝(Machine Learning)
ex) OCR, spam filter
왜 머신러닝을 사용할까?
머신러닝은 전통 프로그래밍과 비교해 다음과 많은 이점들이 있는데요. 머신러닝은 자동으로 학습하고, 프로그램이 훨씬 짧고, 유지 보수가 쉬우며 더 정확도가 높습니다. 또 새로운 데이터에 잘 적응하고 많은 양의 데이터나 복잡한 문제에 대해 인사이트를 얻기 쉽습니다.
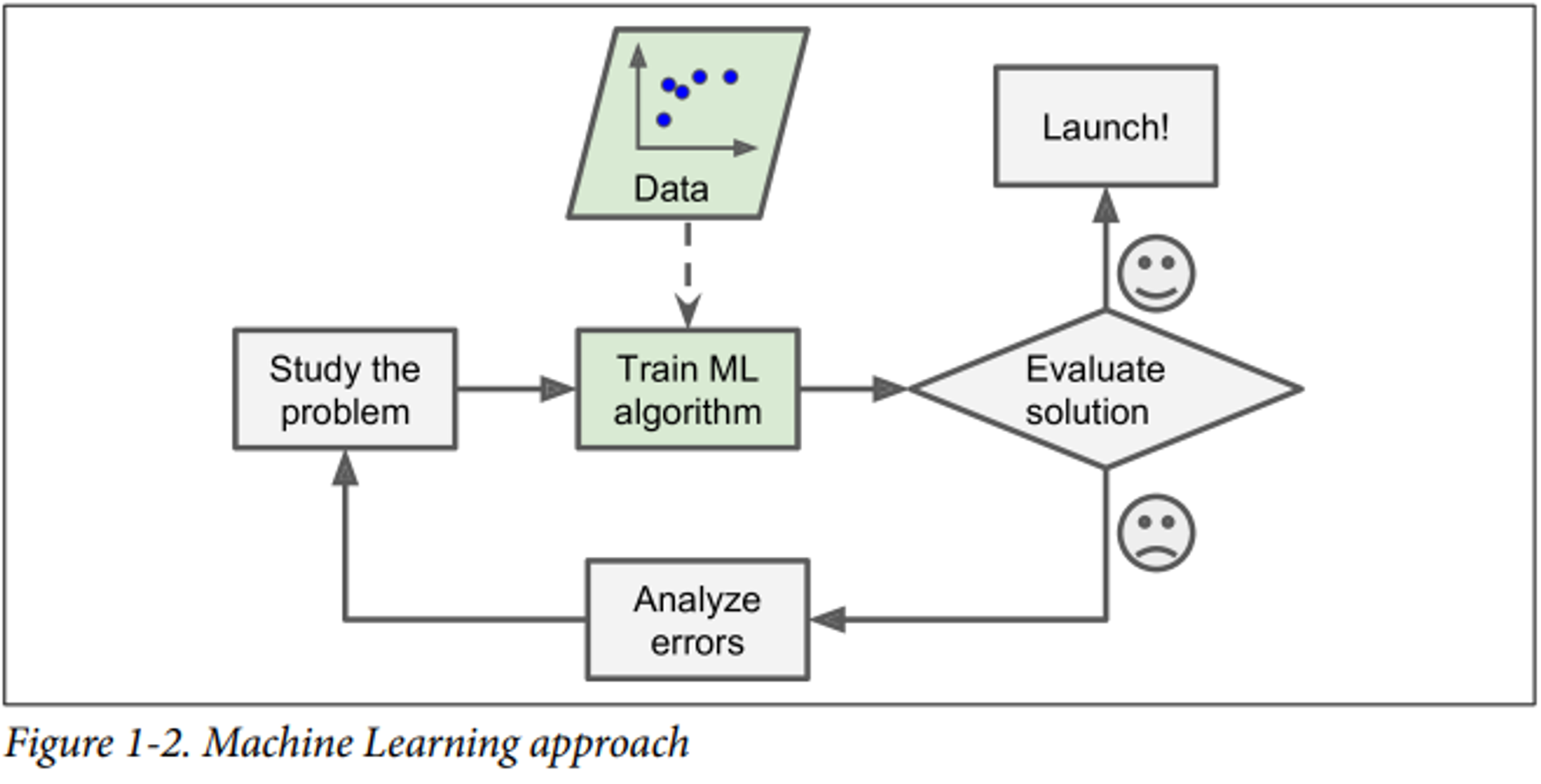
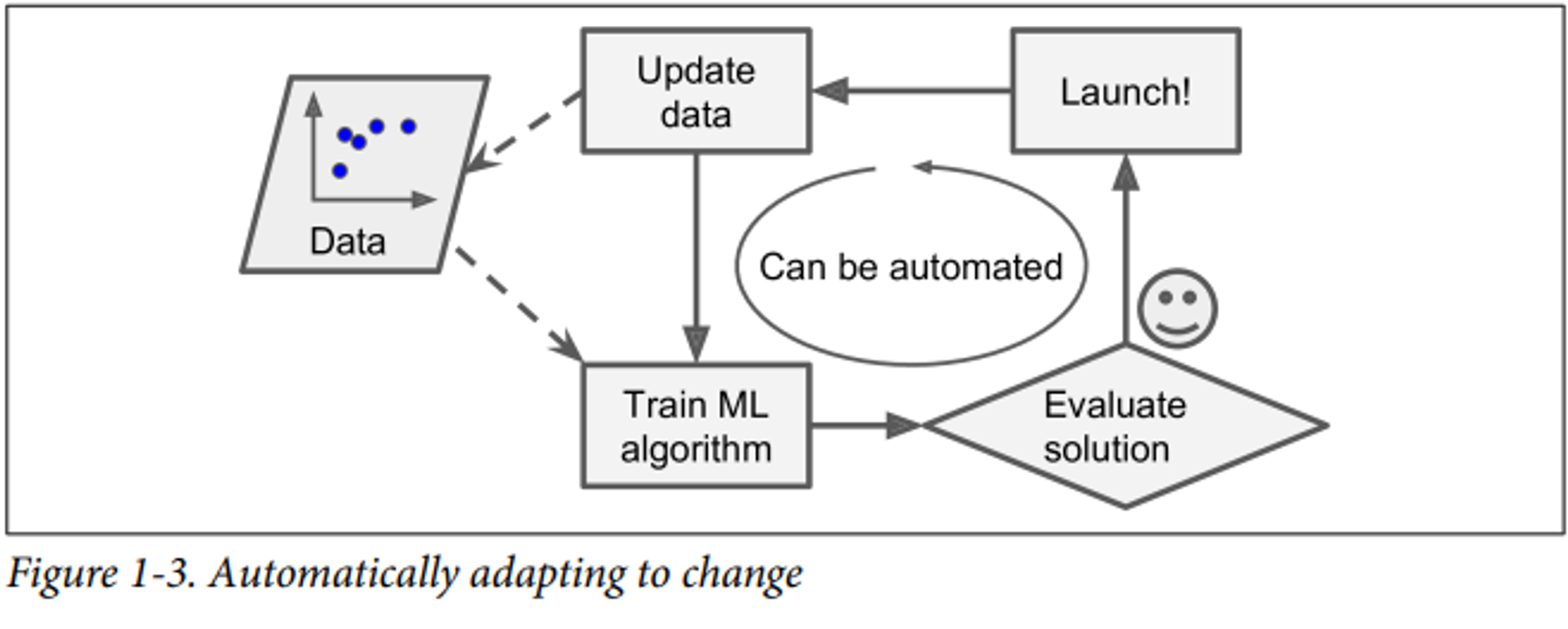
머신러닝을 통해 보이지 않는 패턴을 발견하기도 합니다.
- ☑️ 데이터마이닝(data mining)
- 머신러닝 기술을 적용해 많은 양의 데이터를 분석하여 보이지 않는 패턴을 발견하는 것
📌 머신러닝 시스템 종류
1️⃣ 지도/비지도 학습
다시 말해, 지도/비지도 학습은 답이 정해져 있는 문제를 해결하느냐 아니냐에 따라 지도, 비지도, 준지도, 강화학습으로 구분할 수 있습니다.
지도 학습(Supervised learning)
: 훈련 데이터에 레이블(label)이라는 원하는 답이 포함되있을 경우
.png)
지도 학습의 예는 아래와 같습니다.
-
분류(Classification) : 레이블이 범주형
→ k-Nearest Neighbors, Support Vector Machines (SVMs), Decision Trees and Random Forests -
회귀(Regression) : 레이블이 수치형
→ Linear regression, Logistic Regression※ 몇몇 회귀 알고리즘으로 분류에 사용할 수 있고, 반대로 분류 알고리즘도 회귀에 사용할 수 있습니다.
-
신경망(Neural networks)
비지도 학습(Unsupervised learning)
: 훈련 데이터에 레이블이 포함되어 있지 않은 경우
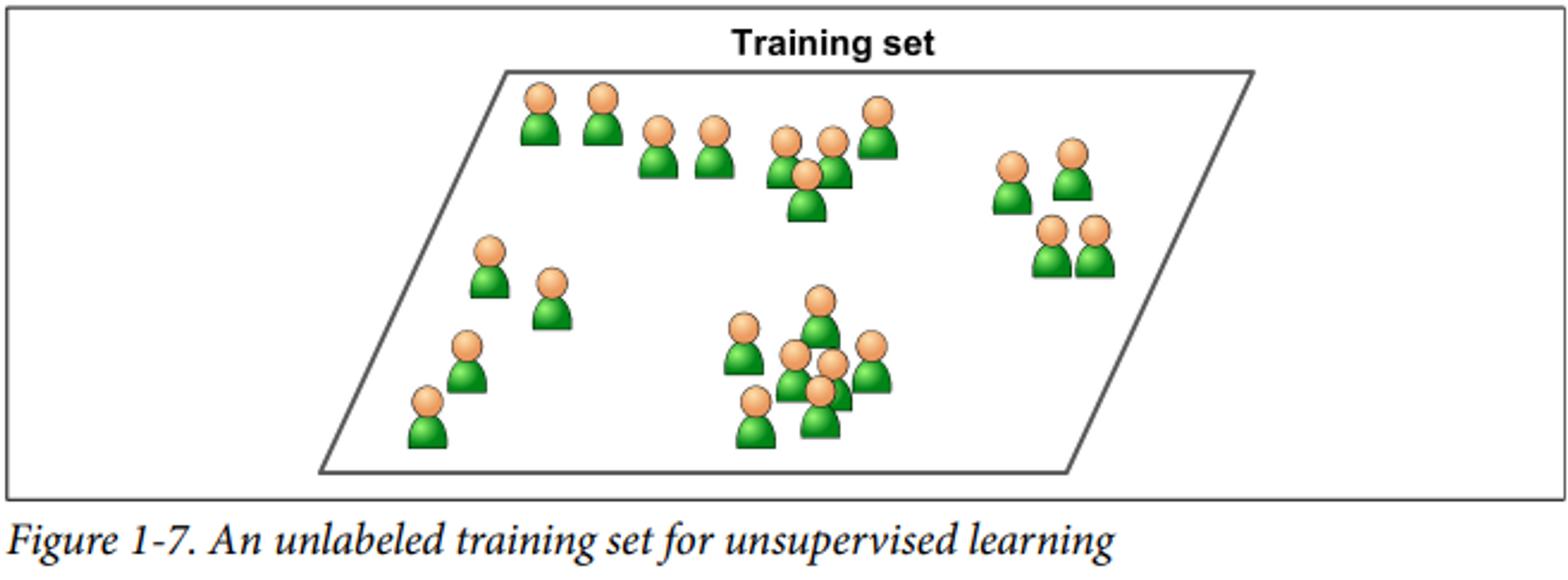
비지도 학습의 예는 아래와 같습니다.
- 군집(Clustering)
→ K-Means, DBSCAN, Hierarchical Cluster Analysis (HCA) -
이상치 탐지(Outlier detection) and 특이치 탐지(novelty detection)
→ One-class SVM, Isolation Forest※ 이상치 탐지는 이미 알려진 유형의 이상치를 식별하고, 특이치 탐지는 알지 못하는 완전히 새로운 유형의 이상치를 식별한다는 차이로 이해한다.
-
Visualization and 차원축소(dimensionality reduction)
→ 주성분 분석(Principal Component Analysis; PCA), Kernel PCA, Locally-Linear Embedding (LLE), t-distributed Stochastic Neighbor Embedding (t-SNE)※ 지도 학습 같은 머신러닝 알고리즘을 수행하기 전에 차원 축소를 사용해 훈련 데이터의 차원을 줄이면, 적은 디스크와 메모리로 더 빨라지고, 성능이 더 좋아지기도 합니다.
- Association rule learning
→ Apriori, Eclat
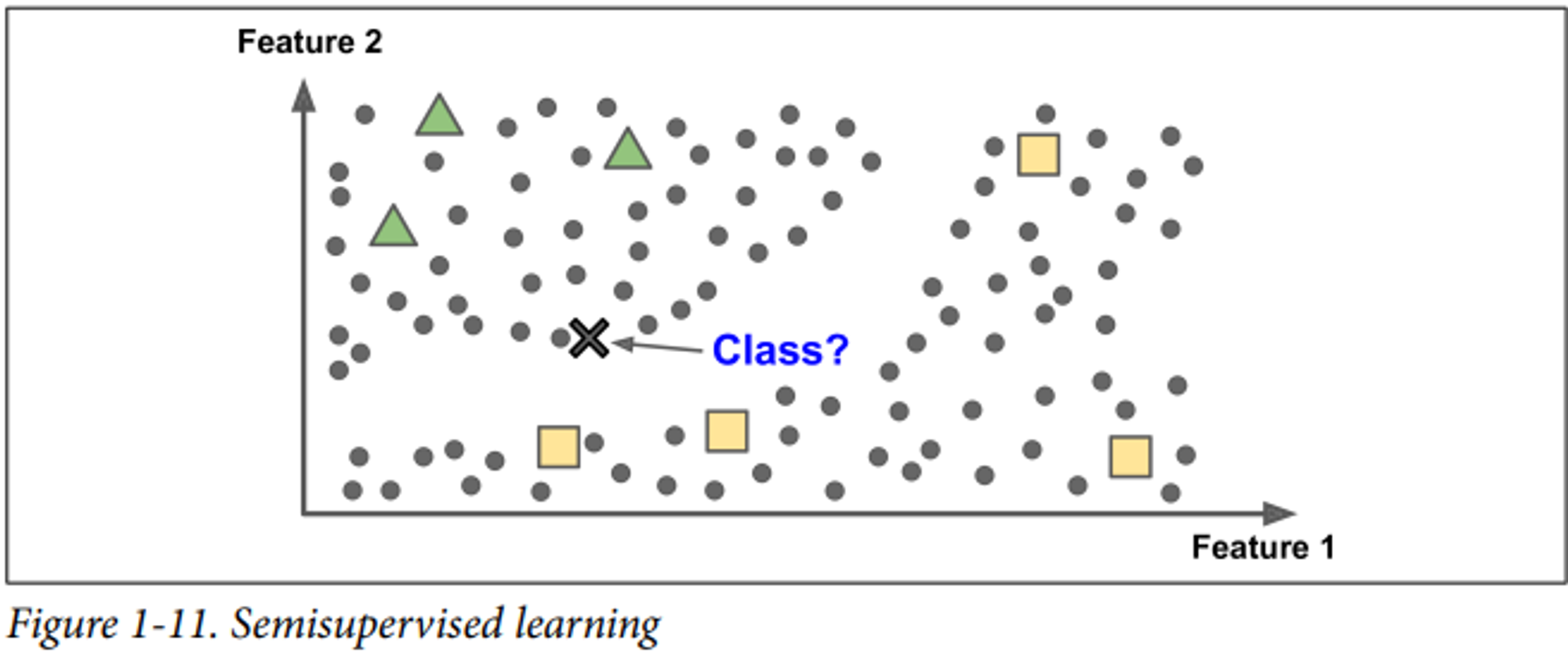
준지도 학습(Semisupervised Learning)
: 훈련데이터에 부분적으로 레이블이 있는 경우, 즉, 지도 학습 + 비지도 학습
e.g. photo-hosting services, such as Google photos(clustering)
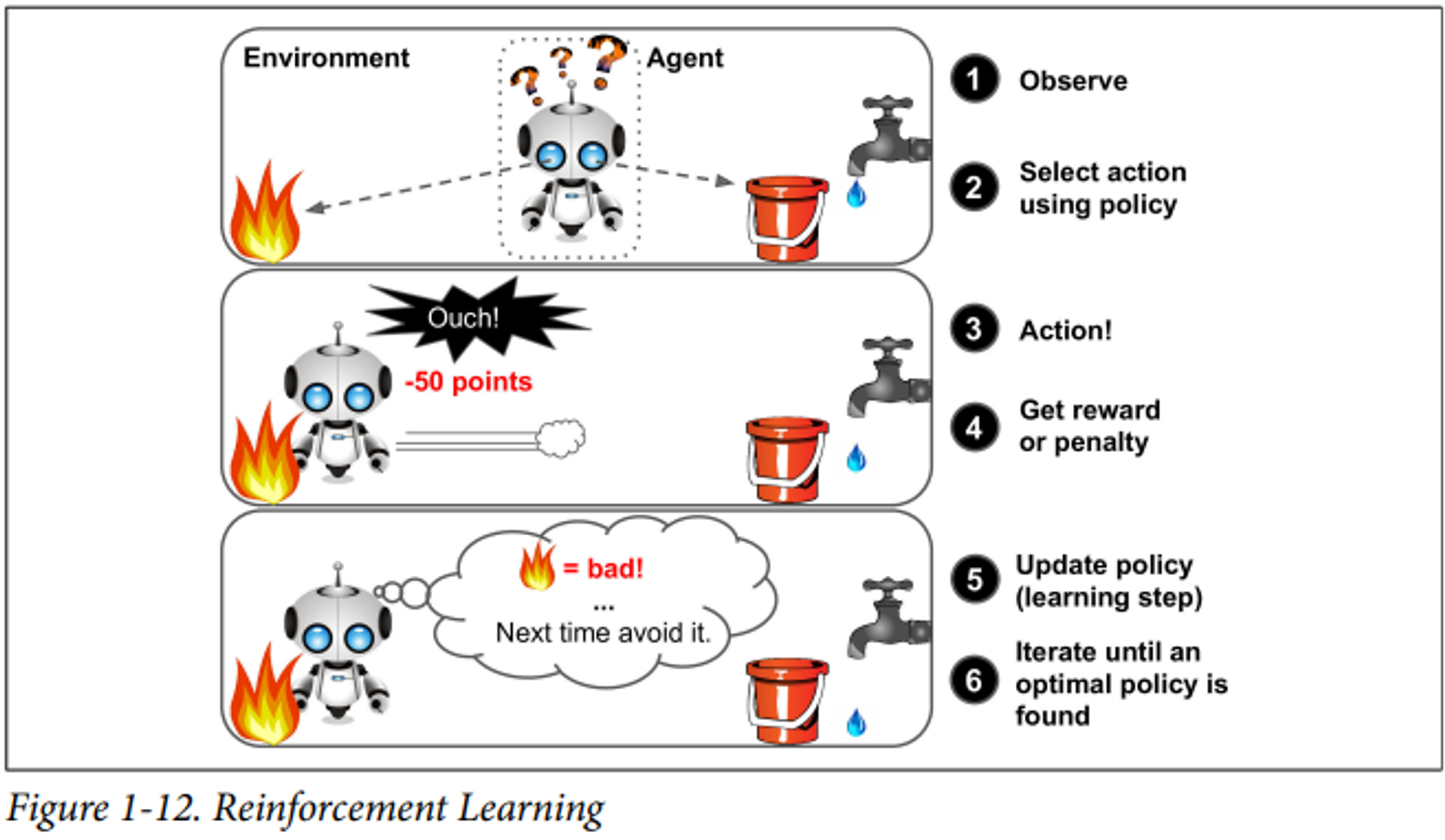
강화 학습(Reinforcement Learning)
: 상황을 관찰하고, 행동을 선택 및 수행한 뒤 이에 따라 보상이나 벌점을 받고 다시 행동을 선택하는 과정으로 돌아가 최적의 행동을 찾는 알고리즘
e.g. AlphaGo program, walking robots
2️⃣ 배치/온라인 학습
배치 학습(Batch learning)
- 점진적으로 학습X 사용 가능한 데이터 모두를 사용해 훈련해야 함.
-
시간과 자원 소모가 큼
→ 때문에 보통 오프라인 학습을 함
- 오프라인 학습(Offline learning)
- 먼저 시스템을 훈련시킨 뒤 제품 시스템에 적용해 더 이상의 학습없이 실행하는 것.
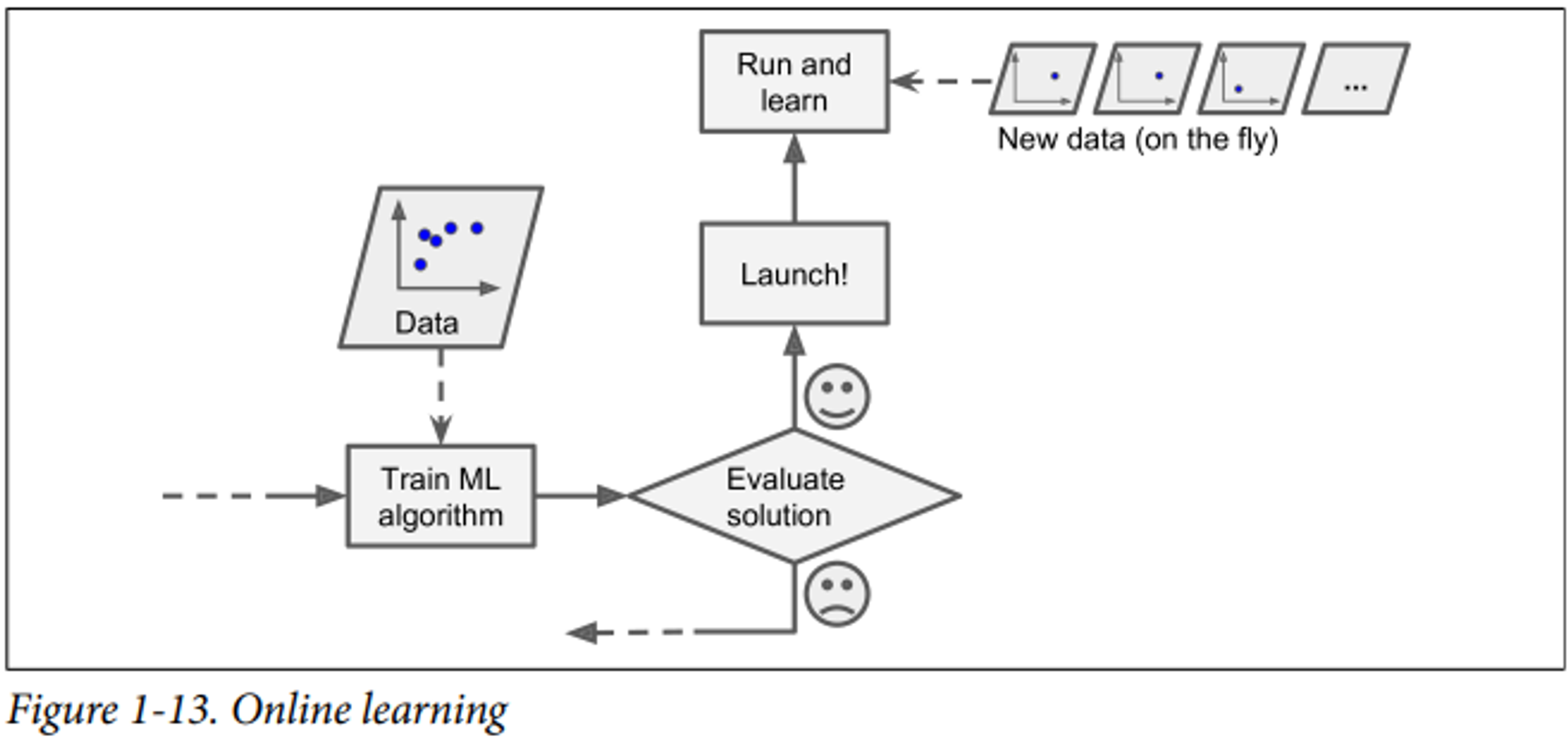
온라인 학습(Online learning)
- 점진적으로 학습O
- 빠르고 저렴함
- great for systems that receive data as a continuous flow (e.g. stock prices) and need to adapt to change rapidly or autonomously
- ☑️ 학습률(learning rate)
- 변화하는 데이터에 적응하는 속도, 온라인 학습에 중요한 파라미터
학습률이 높으면, 새로운 데이터에 빠르게 적응하고 오래된 데이터는 빠르게 잊는다.
학습률이 낮으면, 새로운 데이터를 느리게 학습하고 새로운 데이터나 이상치에 덜 민감하다.
※ Out-of-core learning : using online learning to train systems on huge datasets that cannot fit in one machine’s main memory. usually done offline
3️⃣ 사례 기반/모델 기반 학습
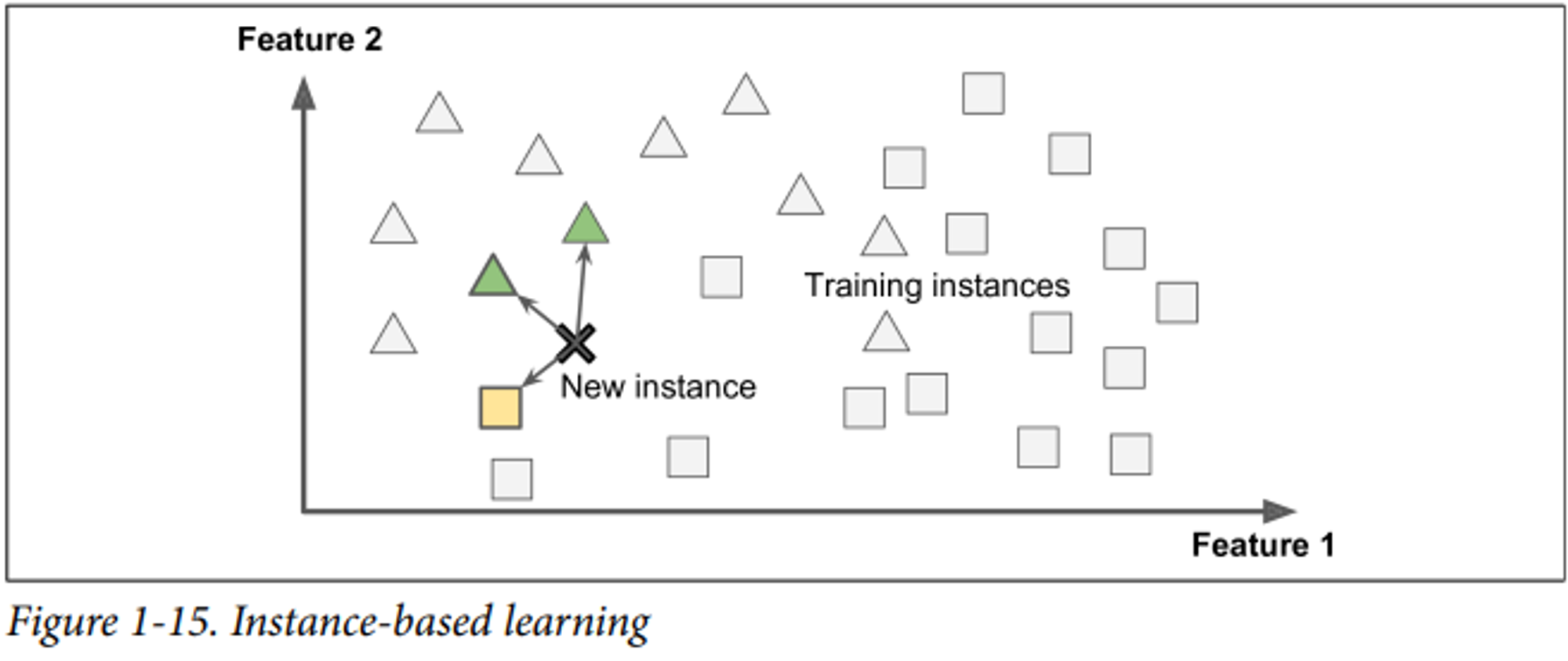
사례 기반 학습(Instance-Based learning)
: 사례를 통해 학습하고, 유사도 측정으로 학습된 데이터와 비교해 새로운 케이스를 일반화하는 방법 e.g. KNN
다시 말해, 단순히 알고 있는 데이터와 새로운 데이터를 비교해 일반화하는 것이다.
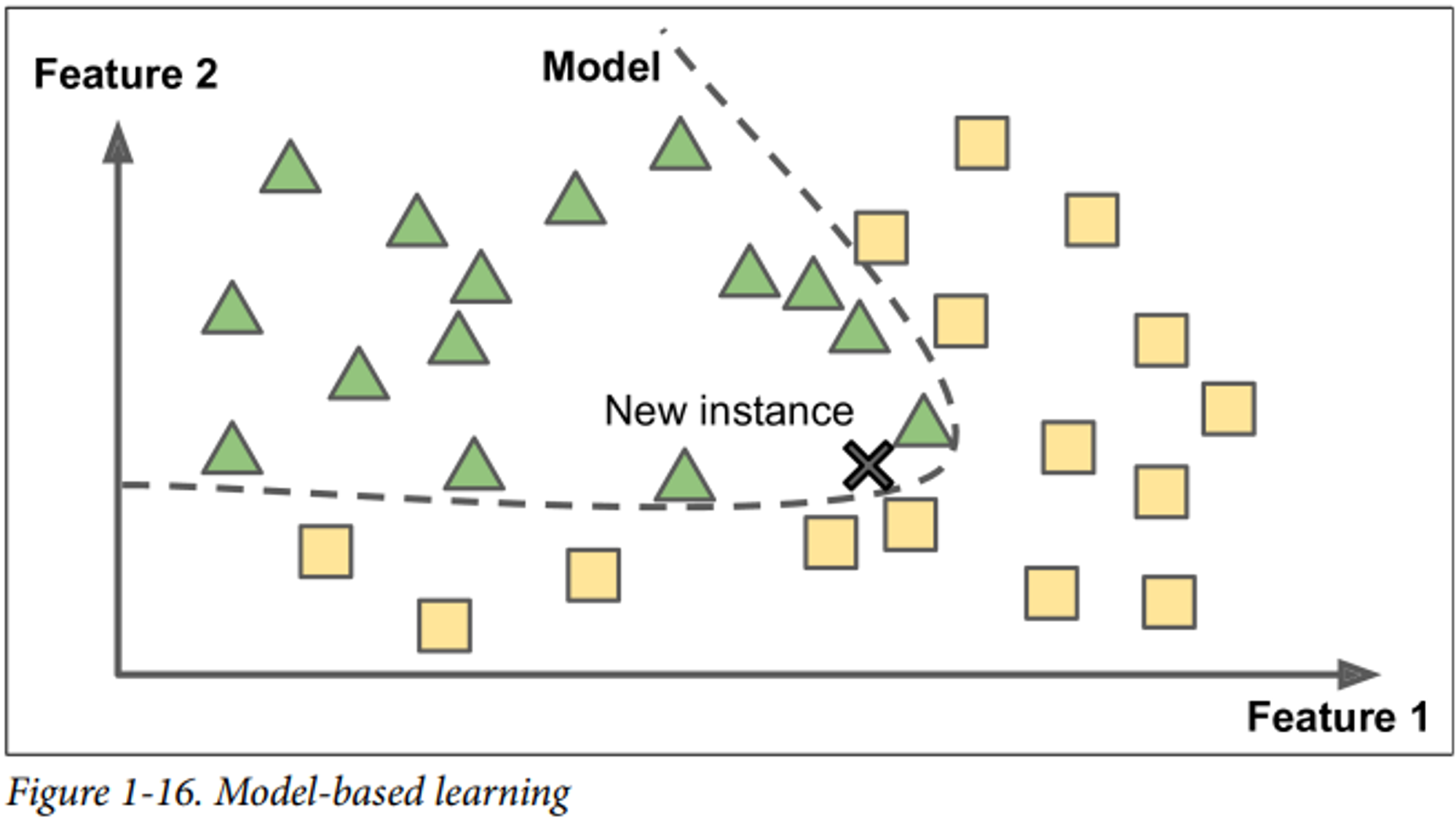
모델 기반 학습(Model-Based Learning)
: 샘플들의 모델을 만들어 예측에 사용하는 것
다시 말해, 훈련 데이터에서 발견한 패턴으로 예측 모델을 만들어 일반화하는 것이다.
📌 전형적인 머신러닝 프로젝트 과정
1) 데이터 불러와 탐색하기
2) 데이터 전처리 및 정제
3) 모델 선택
4) 훈련 데이터로 모델 훈련
5) 새로운 데이터에 모델을 적용해 예측하기(=추론; inference)
모델이 최상의 성능을 내도록 하는 매개변수를 어떻게 알 수 있을까?
- ☑️ 효용함수(utility function)
- 모델이 얼마나 좋은지 측정
- ☑️ 비용함수(cost function)
- 모델이 얼마나 나쁜지 측정
예를 들어, 회귀의 평가지표인 MSE는 값이 클수록 오차가 큰 것이므로 비용함수입니다. 알고리즘 별로 다른 평가지표로 모델의 성능을 측정합니다.
📌 머신러닝의 주요 도전 과제
머신러닝을 할 때에는 나쁜 데이터와 나쁜 알고리즘을 피해 학습 시킬 수 있도록 해야 합니다. 나쁜 데이터와 나쁜 알고리즘이 무엇인지 살펴보고 주의해봅시다.
불충분한 양의 훈련 데이터
간단한 문제여도 머신러닝의 성능을 위해서는 수천개의 데이터가 필요합니다. 데이터가 부족하면 알고리즘 성능을 향상 시키기 어렵습니다.
대표성 없는 훈련 데이터
- 샘플링 잡음(sampling noise) : 샘플이 작아 우연에 의한 대표성 없는 데이터가 생기는 것
- 샘플링 편향(sampling bias) : 잘못된 표본 추출 방법으로 데이터가 대표성을 갖지 못하는 것
예를 들어 전국 소득을 예측하는데 서울시 소득 데이터가 없는 상태로 학습을 시킨다면, 샘플링 편향을 띄게 됩니다.
낮은 품질의 데이터
- 이상치(outlier)가 많은 데이터, 특성이 일부 없는 데이터
관련 없는 특성
“garbage in, garbage out”이라는 말처럼 좋지 않은 데이터를 넣으면 결과가 좋지 않습니다.
따라서 피쳐 엔지니어링을 거쳐 좋은 피쳐를 선택해야 합니다.
-
특성 선택(feature selection) : 가지고 있는 특성 중 유용한 특성을 선택하는 것
- 특성 추출(feature extraction) : 특성을 결합해 더 유용한 특성을 만드는 것(ex 차원 축소)
- 새로운 데이터를 수집해 새로운 특성 만들기
훈련 데이터 과대적합
- 과대적합
- 모델이 너무 복잡해서 데이터를 학습하지 못하는 상황
훈련 데이터에 너무 들어맞는 모델이면, 새로운 데이터가 들어왔을 때 성능이 안 좋을 수가 있습니다. 즉, 오버 피팅이 되면 일반성이 떨어지게 됩니다.
과대적합 해결 기법
- 모델에 제약을 가해 단순화
- 더 적은 파라미터가 있는 모델 선택
- 훈련 데이터를 많이 모으기
- 훈련 데이터의 잡음 제거(오류 수정, 이상치 제거)
훈련 데이터 과소적합
- 과소적합
- 모델이 너무 단순해서 데이터를 학습하지 못하는 상황
과소적합 해결 기법
- 더 많은 파라미터가 있는 모델 선택
- 학습 알고리즘에 더 좋은 피쳐 제공 (feature engineering)
- 모델의 제약 줄이기